这片文章的起因是源于一个 YouTube 上的视频 Golang UK Conf. 2016 - Liz Rice - What is a container, really? Let’s write one in Go from scratch,看了之后觉得很不错,一个主题可以贯穿起来很多 Linux 的知识,也对容器、Docker 技术的原理做了次实践,对理解容器的特点和局限性很有帮助,这里我做了些修改和扩展然后再分享给大家。
要想把这些讲清楚需要涉及到的知识点和命令都不少,怎奈鄙人才疏学浅,难免会有纰漏,有错误的地方还请大家多多指正。
namespace 初识
Docker 是一个基于 namespace、cgroup、Union FS 等等技术的一个开源容器引擎,很多人都会觉得 Docker 是个新兴技术,其实不然,其主要隔离技术 Namespace 技术早在 Linux 内核版本为 2.6 时候就差不多完成了(像 Ubuntu 16.04 发行版本的内核基本上都是 4.4,CentOS 7 则普遍 3.10 )。
Linux Namespace 是 Linux 提供的一种内核级别环境隔离的方法。
要想实现隔离的效果,需要完成的东西又有哪些呢?其实如果你安装了 gcc 工具链(安装 golang 之后就会有了),那么使用 man namespaces 命令就可以了解到 namespace 技术的大概,也可查看在线手册。
这里简单地搬运了些知识点,首先是 Linux 提供的具体的隔离内容:
| Namespace |
系统调用参数 |
内核版本 |
隔离内容 |
| UTS (Unix Time-sharing System) |
CLONE_NEWUTS |
Linux 2.4.19 |
主机名与域名 |
| IPC (Inter-Process Communication) |
CLONE_NEWIPC |
Linux 2.6.19 |
信号量、消息队列和共享内存 |
| PID (Process ID) |
CLONE_NEWPID |
Linux 2.6.19 |
进程编号 |
| Network |
CLONE_NEWNET |
Linux 2.6.24 |
网络设备、网络栈、端口等等 |
| Mount |
CLONE_NEWNS |
Linux 2.6.29 |
挂载点(文件系统) |
| User |
CLONE_NEWUSER |
Linux 3.8 |
用户和用户组 |
还设计到三个系统调用(system call)的 API:
- clone():用来创建新进程,与 fork 创建新进程不同的是,clone 创建进程时候运行传递如 CLONE_NEW* 的 namespace 隔离参数,来控制子进程所共享的内容,更多内容请查看clone 手册
- setns():让某个进程脱离某个 namespace
- unshare():让某个进程加入某个 namespace 之中
查看进程 namespace
/proc/[pid]/ns/ 目录下包含了某个进程的 namespace 所属,在 shell 中 $$ 为当前进程 PID 所以可以:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
$ ls -l /proc/$$/ns
total 0
lrwxrwxrwx 1 root root 0 Jan 5 00:13 cgroup -> cgroup:[4026531835]
lrwxrwxrwx 1 root root 0 Jan 4 06:18 ipc -> ipc:[4026531839]
lrwxrwxrwx 1 root root 0 Jan 4 06:18 mnt -> mnt:[4026531840]
lrwxrwxrwx 1 root root 0 Jan 4 06:18 net -> net:[4026531957]
lrwxrwxrwx 1 root root 0 Jan 4 06:18 pid -> pid:[4026531836]
lrwxrwxrwx 1 root root 0 Jan 4 06:18 user -> user:[4026531837]
lrwxrwxrwx 1 root root 0 Jan 4 06:18 uts -> uts:[4026531838]
$ readlink /proc/$$/ns/uts
uts:[4026531838]
$ readlink /proc/$PPID/ns/uts
uts:[4026531838]
|
/proc/[pid]/mounts 目录展现了进程的挂载点,而 /proc/[pid]/mountinfo 里的内容更详细。
Linux 系统调用
操作系统的进程空间可分为用户空间和内核空间,它们需要不同的执行权限。其中系统调用运行在内核空间。
系统调用,指运行在用户空间的程序向操作系统内核请求需要更高权限运行的服务。系统调用提供用户程序与操作系统之间的接口。大多数系统交互式操作需求在内核态运行。如设备IO操作或者进程间通信。
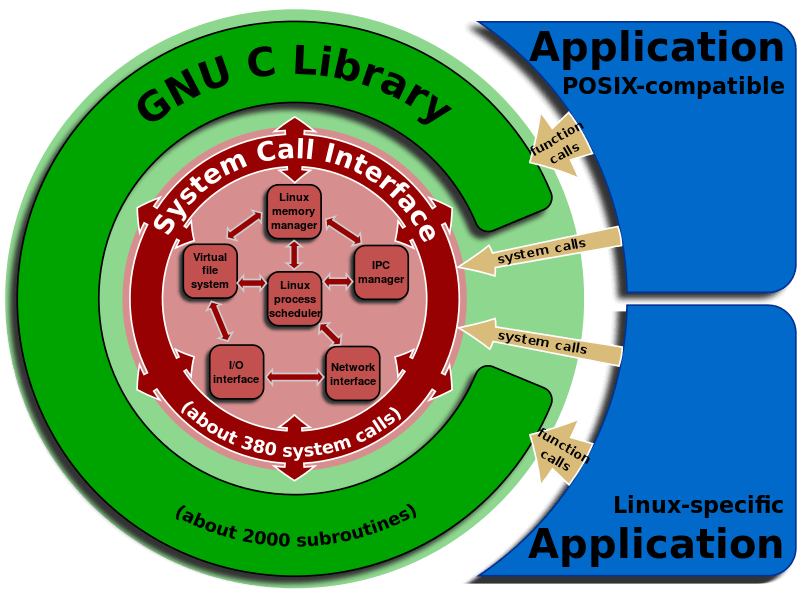
也就是说,如果自己程序生成的可执行文件,除了一些简单的变量加来加去之外,大多数有意思的功能都是通过系统调用来完成的,平时没有感知到,是因为库函数、动态链接库封装屏蔽了这些。
程序设计中没有什么是加一层解决不了的,如果有那就再加一层。所以 syscall 可以作为一个兼容层、移植层,可以通过实现一组 syscall 接口,用来来模拟 Linux。
Linux 中提供了两个工具: starce 和 ptrace 用来调试监控某个进程的系统调用。
Linux 进程
Linux 下可以通过 ps -ef 命令打印出当前操作系统中正在执行的进程,其实还有一个更有意思的命令 pstree ,这个命令会以树的形式输出当前的进程。
为什么这些进程会形成一个树的形状?这是因为在 Linux 内核启动之后只会有一个 pid 为 0 的 运行在内核态的 idle 进程,随后在系统启动过程中,会通过该进程 fork 出 PID 为 1 的 init 进程和 PID 为 2 的 kthreadd 进程。
init 进程负责初始化系统,并最后运行在用户空间。在系统启动完成完成后,init将变为守护进程监视系统其他进程。init 有不同实现,如最初的 init 到 System V 再到 Systemd,常用的 service 命令就是最初由 init 实现的,用来管理各种服务的守护进程,关于 init 的演进可以参考 linux 系统管理程序。
kthreadd 内核线程都是直接或者间接的以 kthreadd 为父进程,该进程负责管理和调度其他的内核进程。
在 ps -ef 命令下可以看到这些进程, pstree 可以看到用户进程,还有一个知识点就是用户空间的进程 PID 都是大于 1000 的。
Uinx 的哲学中接口的设计都是高度正交的,通过 fork 和 exec系列的组合就可以完成多进程的操作。
fork() 默认会进程复制当前进程自身(代码段、数据段、环境变量等等)来快速创建子进程,子进程会从调用 fork() 的地方开始执行,也就是在代码的 fork() 处进行了分叉。fork() 返回值在父进程中为创建的子进程的 PID,在子进程返回 0 ,出现错误返回负值,可以通过返回值来进行区别操作(如父进程里 wait 子进程)。
exec 系列 会用一个新的程序来替换现在的整个进程,其会将程序整个加载到现在的进程中,然后从头开始运行,如更新了 bash 的某些配置之后可以用 exec bash 命令来利用新 bash 线程替换掉当前的进程。
此外还有两个有名的进程:
孤儿进程:个父进程退出,而它的一个或多个子进程还在运行,那么那些子进程将成为孤儿进程。孤儿进程将被 init 进程(进程号为1)所收养,并由 init 进程对它们完成状态收集工作。
僵尸进程:一个进程使用 fork 创建子进程,如果子进程退出,而父进程并没有调用 wait 或 waitpid 获取(处理)子进程的状态信息,那么子进程的进程描述符仍然保存在系统中。这种进程称之为僵死进程,在 top 命令里是可以看到。
所以通过一顿高度正交的 fork exec 操作,会形成一颗进程树,这里可以通过 pstree 演示下:
1
2
3
4
5
6
7
8
9
|
$ pstree -pa $$
zsh,1680
└─pstree,130454 -pa 1680
$ sleep 10s &
[1] 130554
$ pstree -pa $$
zsh,1680
├─pstree,130562 -pa 1680
└─sleep,130554 10s
|
其实在执行 pstree -pa $$ 就可以看到他是基于当前终端的子进程。
namespace 实践
为了最好的体验还是在 Linux 内核 3.8 以上的系统上进行(这里使用的 Ubuntu server 16.04, Linux 4.4)。为什么不用 docker for windows 或者 docker for mac 呢?因为这两个其实还是是在 linux 虚拟机上运行 docker 的,docker for windows 需要将 linux 虚拟机装在开启 hyper-v 的 win10 专业版上,而 docker for mac 使用通过 HyperKit 运行 linux 虚拟机。为了方便,使用 golang 来演示循序渐进的达到 Docker 的体验。
docker 是虚拟机吗
由前面的 namespace 的知识可以知道 Docker 是比虚拟机的虚拟化程度更弱、效率更高的线程级别的隔离,下面的示例可以验证这一点。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
$ docker run alpine sleep 1m &
$ pstree -pa $$
zsh,1680
├─docker,7314 run alpine sleep 1m
│ ├─{docker},7315
│ ├─{docker},7316
│ ├─{docker},7317
│ ├─{docker},7318
│ ├─{docker},7321
│ ├─{docker},7324
│ └─{docker},7325
└─pstree,7431 -pa 1680
$ ps -ef |grep "sleep 1m"
creaink 7314 1680 0 03:56 pts/1 00:00:00 docker run alpine sleep 1m
root 7362 7344 0 03:56 ? 00:00:00 sleep 1m
|
上面的例子使用 alpine 镜像运行了 sleep 1m 这个命令即休眠一分钟,直接使用 pstree 可以证实最后其虚拟化程度也就是线程级别的。后面的 ps 命令揭示的是其实这里有两个命令运行着 sleep 1m,这是因为 docker 分为 docker daemon 和 docker client,docker(docker client) 命令通过 REST API 将用户的命令传递给 dockerd(docker daemon),也就是最后的实际工作的进程是 dockerd 下的子进程,这就是为什么在终端里运行 docker 运行容器之后,而关闭终端(父进程)容器也不会被终止掉。
版本 zero
先来一个基础的版本,实现一个简单的功能:将传递给程序的命令利用子进程运行:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
package main
import (
"fmt"
"os"
"os/exec"
"syscall"
)
func main() {
switch os.Args[1] {
case "run":
run()
default:
fmt.Printf("do nothing, exit!!!")
}
}
func run() {
fmt.Printf("running %v\n", os.Args[2:])
cmd := exec.Command(os.Args[2], os.Args[3:]...)
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
must(cmd.Run())
}
func must(err error) {
if err != nil {
panic(err)
}
}
|
命名该程序为 docker-1.go 之后就可以使用 go run docker-1.go run echo hello 来 代理 运行命令一些命令。
甚至可以直接使用 go run docker-1.go run /bin/bash 来将子进程的 shell 衔接到当前终端上,注意 shell prompt 的变化(由 zsh 变为 bash 样式),在下面的例子中将尝试更改 hostname:
1
2
3
4
5
6
7
8
9
10
11
|
$ go run docker-0.go run /bin/bash
running [/bin/bash]
creaink@ubuntu:~/share$ hostname
ubuntu
creaink@ubuntu:~/share$ sudo hostname docker
creaink@ubuntu:~/share$ hostname
docker
creaink@ubuntu:~/share$ exit
# 这里的 hostname 也跟着变了
$ hostname
docker
|
通过最后的命令可以看到 hostname 也跟着变了,这里就没有实现前面提到的 UTS 隔离。
版本 one
可以为 cmd 加上 SysProcAttr,利用 CLONE_NEWUTS 参数来实现其子进程的 UTS 隔离,zero 版本更改的部分如下:
1
2
3
4
5
6
7
8
9
10
|
func run() {
// ...
cmd.Stderr = os.Stderr
cmd.SysProcAttr = &syscall.SysProcAttr{
Cloneflags: syscall.CLONE_NEWUTS,
}
must(cmd.Run())
}
|
上述更改之后的文件存为 docker-1.go 然后探究:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
$ sudo share go run docker-1.go run /bin/bash
running [/bin/bash]
root@ubuntu:~/share$ readlink /proc/$PPID/ns/uts
uts:[4026531838]
# 与父进程的 namespace uts 已经不同了
root@ubuntu:~/share$ readlink /proc/$$/ns/uts
uts:[4026532634]
# 更改 hostname 也不会变化了
root@ubuntu:~/share$ sudo hostname docker
root@ubuntu:~/share$ hostname
docker
root@ubuntu:~/share$ exit
$ hostname
ubuntu
|
通过上面的 readlink /proc/[PID]/ns/uts 和 hostname 可以看出来,在新的进程里已经实现了 UTS 的隔离了。那么 CLONE_NEWUTS 这个参数 go 是如何在创建子进程时候传入的呢?答案是利用了 clone 系统调用来完成的,这里可以简单的利用 strace 命令追踪下系统调用:
1
2
3
4
5
6
7
8
9
|
# go run 系统调用有干扰项,这里编译下
$ go build docker-1.go
# 这里我们只关心 clone,利用 grep 过滤下
$ strace ./docker-1 run echo hi |& grep "clone\|execv"
execve("./docker-1", ["./docker-1", "run", "echo", "hi"], [/* 26 vars */]) = 0
clone(child_stack=0xc820035fc0, flags=CLONE_VM|CLONE_FS|CLONE_FILES|CLONE_SIGHAND|CLONE_THREAD) = 15932
clone(child_stack=0xc820031fc0, flags=CLONE_VM|CLONE_FS|CLONE_FILES|CLONE_SIGHAND|CLONE_THREAD) = 15933
clone(child_stack=0xc820033fc0, flags=CLONE_VM|CLONE_FS|CLONE_FILES|CLONE_SIGHAND|CLONE_THREAD) = 15934
clone(child_stack=0, flags=CLONE_NEWUTS|SIGCHLD) = -1 EPERM (Operation not permitted)
|
前面的三个 clone 其实是 go 创建的一些自己的进程(可能用 c 来实现会更干净些),可以在 root 用户下开两个终端一个 strace ./docker-1 run sleep 10s |& grep "clone\|execv", 另一个 watch pstree -pa [PID] (这里的 PID 是前面终端的 PID)观察验证。可以看到这三个 clone 的调用采用的是默认的参数:CLONE_VM|CLONE_FS|CLONE_FILES|CLONE_SIGHAND|CLONE_THREAD,其含义可在上面提到的 clone 手册 里查阅到。
最后的一个 clone 系统调用参数就很明显的是在程序里自行设定的 CLONE_NEWUTS,SIGCHLD 参数默认要添加上的:共享信号,即子进程的生命周期发生变化时候会通过 SIGCHLD 信号告知父进程。
版本 two
这一版本要要在上个版本实现了 UTS 隔离的情况下进而实现 PID 隔离,很容易会想到在调用时候加上 CLONE_NEWPID 即可实现。为了检验,就需要在代理生成的子进程下再生成一个子进程:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
// 在 main 中加上 child 的 case
func main() {
switch os.Args[1] {
// ...
case "child":
child()
// ...
}
}
// run 修改为下面
func run() {
cmd := exec.Command("/proc/self/exe", append([]string{"child"}, os.Args[2:]...)...)
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
cmd.SysProcAttr = &syscall.SysProcAttr{
Cloneflags: syscall.CLONE_NEWUTS | syscall.CLONE_NEWPID,
}
must(cmd.Run())
}
// 加一个函数 child
func child() {
fmt.Printf("running %v as pid: %d\n", os.Args[2:], os.Getpid())
cmd := exec.Command(os.Args[2], os.Args[3:]...)
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
must(syscall.Sethostname([]byte("InNamespace")))
must(cmd.Run())
}
|
上面的程序需要解释下的是 linux 系统中有个符号链接:/proc/self/exe 它代表当前程序,所以在 run 函数里面调用程序本身并加上 child 参数,以实现 隔一层 进程完成预设命令的指向,方便观察结果。
1
2
3
4
5
6
7
8
9
10
11
12
13
|
# 进入到子进程所创建的 shell 中,输出当前 PID,可以看到已经实现隔离
$ sudo go run docker-2.go run /bin/bash
running [/bin/bash] as pid: 1
root@InNamespace:~/share$ echo $$
5
root@InNamespace:~/share$ ps
PID TTY TIME CMD
18868 pts/1 00:00:00 sudo
18869 pts/1 00:00:00 go
18886 pts/1 00:00:00 docker-2
18890 pts/1 00:00:00 exe
18894 pts/1 00:00:00 bash
18973 pts/1 00:00:00 ps
|
上面出现了两个矛盾的结果: 运行输出了 running [/bin/bash] as pid: 1 和 echo $$ 的 PID 明显是隔离出来的(用户空间的进程不可能小于 1000)而 ps 显示的进程 PID 明显是没有隔离出来的。
其实这时候是已经实现了隔离,而 ps 命令显示的 PID 不对,甚至 ps -ef 还可以查看到整个系统的所有进程,这是因为 ps 命令只是简单的查看了文件系统里的 /proc 目录而给出内容信息,这时候进程的文件系统是继承于父进程的,所以虽然已经位于新的 PID 命名空间了,但是 ps 还无法正常工作。
所以可以尝试挂载虚拟文件夹 proc 到本地一个文件夹下查看检验下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
$ sudo go run docker-2.go run /bin/bash
root@InNamespace:~/share$ mkdir proc
root@InNamespace:~/share$ mount -t proc proc proc
# 这时候 share/proc 里的内容是正常的,但是 ps 还是查看的 /proc 下的内容
root@InNamespace:~/share$ ls proc
1 cmdline execdomains kallsyms loadavg mtrr slabinfo timer_list zoneinfo
22 consoles fb kcore locks net softirqs timer_stats
5 cpuinfo filesystems keys mdstat pagetypeinfo stat tty
...
# 但是退出之后到宿主机(父进程)上查看其挂载点
root@InNamespace:~/share$ exit
$ mount
...
proc on /mnt/hgfs/share/proc type proc (rw,relatime)
proc on /mnt/hgfs/share/proc type proc (rw,relatime)
|
自制容器(子进程)其内的挂载操作会直接影响宿主机(父进程)挂载点,并且 /proc 下的内容需要重新挂载,所以挂载点需要进行进一步地隔离。
版本 three
自然的想到为 clone 进程时候加上 CLONE_NEWNS 即可达到挂载点隔离的效果,使用该参数之后创建子进程会复制一份父进程的挂载挂载点,之后子进程里的挂载操作不会影响到父进程的挂载点。但是同时要处理挂载 /proc 目录的问题,除了挂载点能不能直接更换所继承的文件系统?
从下面 Docker 分层文件系统中示意图可以看到,用户空间的文件系统(rootfs)是可以更换的,通过 chroot 系统调用可以更改(jail)当前正在运行的进程及其子进程的根目录。

所以这里找来了一个非常精简的 alpine rootfs, 解压到 /var/lib/alpine 目录下以备后用。
所以更改之后的第三版本是这样的:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
func run() {
// ..
cmd.SysProcAttr = &syscall.SysProcAttr{
Cloneflags: syscall.CLONE_NEWUTS | syscall.CLONE_NEWPID | syscall.CLONE_NEWNS,
}
// ..
}
func child() {
// ..
must(syscall.Sethostname([]byte("InNamespace")))
must(syscall.Chroot("/var/lib/alpine"))
must(os.Chdir("/"))
must(syscall.Mount("proc", "proc", "proc", 0, ""))
must(cmd.Run())
}
|
更改之后的文件命名为 docker-3.go ,由于之前没隔离而有挂载 proc,所以需要记得 umount proc,随后:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
# 运行 bash 会出错,这是因为更换了 alpine 的 rootfs 之后只有没有了 bash 命令
$ sudo go run docker-3.go run /bin/bash
panic: fork/exec /bin/bash: no such file or directory
$ sudo go run docker-3.go run /bin/sh
# 进入容器(子进程shell)后发现 PID 正常了,ps 能够直接使用
# alpine 的 shell 提示符更改下
/ # export PS1='root@$(hostname):$(pwd)$ '
root@InNamespace:/ $ ps
PID USER TIME COMMAND
1 root 0:00 /proc/self/exe child /bin/sh
6 root 0:00 /bin/sh
9 root 0:00 ps
# mount 显示的挂载点也非常简单,也就是在程序里自行挂载的 proc,这时候 top 也是正常的
root@InNamespace:/ $ cat /proc/self/mountinfo
237 147 0:64 / /proc rw,relatime shared:88 - proc proc rw
root@InNamespace:/ $ exit
$ mount
...
proc on /var/lib/alpine/proc type proc (rw,relatime)
|
自制容器里 ps 已经能够正常工作了,但退出退出容器后,却发现容器内的挂载是会传播到父进程的,这是因为 systemd 将默认的 mount namespace 的事件传播机制定义成了 MS_SHARED,可以使用 findmnt -o TARGET,PROPAGATION 命令查看目录的 propagation。总体的有:共享挂载(shared mount)、从属挂载(slave mount)和私有挂载(private mount)
在 sudo unshare --mount --uts /bin/bash 里是可以的隔离挂载的,这是因为改变了 mount 的 propagation 为 private。如何改变呢,只需要利用 mount 系统调用更改下父目录,其下的子目录就会更变传播方式,如:
1
2
3
4
5
6
7
8
9
10
|
# 利用 root 用户探究下为什么可以实现挂载的隔离
$ strace unshare --mount --uts /bin/echo hi |& grep mount
execve("/usr/bin/unshare", ["unshare", "--mount", "--uts", "/bin/echo", "hi"], [/* 26 vars */]) = 0
mount("none", "/", NULL, MS_REC|MS_PRIVATE, NULL) = 0
# 照葫芦画瓢
$ strace mount --make-rshared / |& grep mount
execve("/bin/mount", ["mount", "--make-rshared", "/"], [/* 21 vars */]) = 0
open("/lib/x86_64-linux-gnu/libmount.so.1", O_RDONLY|O_CLOEXEC) = 3
mount("none", "/", NULL, MS_REC|MS_SHARED, NULL) = 0
|
但是在 syscall 当中就需要手动的以 private 的方式 mount 一遍根目录以达到效果(要在 chroot 之前):
1
2
3
4
5
6
7
8
9
10
11
|
func child() {
// ..
must(syscall.Sethostname([]byte("InNamespace")))
must(syscall.Mount("", "/", "", uintptr(syscall.MS_PRIVATE|syscall.MS_REC), ""))
must(syscall.Chroot("/var/lib/alpine"))
must(syscall.Mount("proc", "/proc", "proc", 0, ""))
must(os.Chdir("/"))
must(cmd.Run())
}
|
最后运行一下是可以发现,隔离有效的,可以在其内使用 mount --bind a b 试试。处理 chroot 更换更目录还可以使用 PivotRoot + mount MS_BIND 的方式,参考。
版本 next
其实到最后会发现,容器就是一些按一定规则被限制继承父进程的某些资源的子进程。
如果后续继续完善其他的 namespace 然后再加以 cgroups 限制 CPU、内存、磁盘、网络等,然后在加上分层存储 Union FS,可能就是完成了一个真正意义上的简化的 Docker。
参考